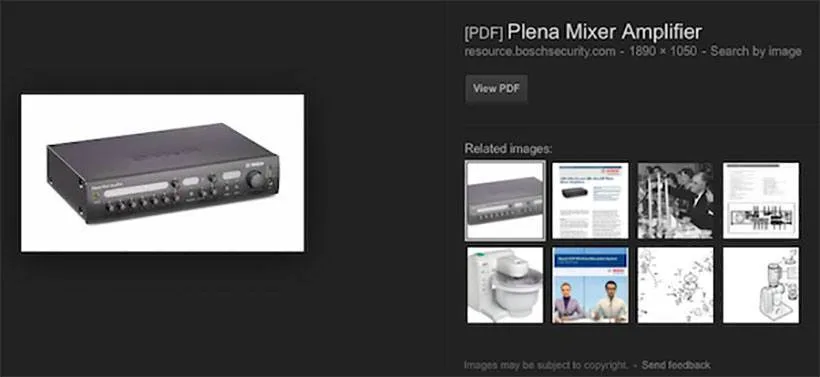
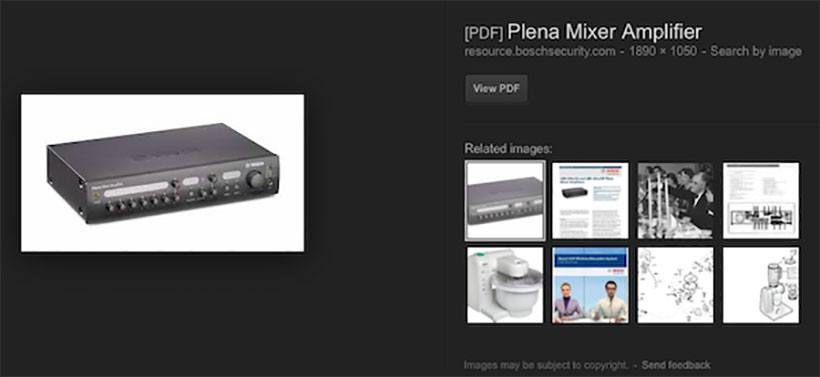
Google’ın internetteki her şeyi dizinlemeyi istediği bir sır değil. Arama devi, dizinleme kapasitesini optimize etmek adına büyük paralar harcıyor. Çabalarının karşılığını alıyor gibi gözüken Google, şimdi de taranmış PDF dosyalarında bulunan resimleri dizinliyor.
İLGİNİZİ ÇEKEBİLİR
Google Gemini artık otomobillerde Google Asistan’ın yerini almaya başladı

Google Finance Android’e geldi, iPhone sürümü de yolda

Google Fitbit Air için ilk güncellemeyi yayınladı
Google Chrome, kişisel bilgileri doldurma şeklini genişletiyor

Google Home Speaker’ın gizli kalan detayı erken satış sayesinde ortaya çıktı
PDF dosyalarından gelen resimler, Google arama motorunun görsel arama bölümünde “PDF” damgasıyla gösteriliyor. Resmin yanına yerleştirilen bir bağlantı, kullanıcıları doğrudan söz konusu görselin bulunduğu PDF dosyasına yönlendiriyor.
Google’ın böyle bir yol seçmesinin nedeni, PDF dosyasındaki bir görsele doğrudan bağlantı vermenin mümkün olmaması. Dolayısıyla kullanıcıların ön izlemenin ardından resmi görmek için PDF dosyasını açması gerekiyor. Google, taranan PDF dosyalarındaki metinleri dizinlemek için 2008’den bu yana OCR teknolojisinden faydalanıyor.
Resimlerin ayıklanabilmeleri ve aranabilir olmaları, PDF’lerin aranabilmesinden sonraki adımı teşkil ediyor. Google’ın OCR teknolojisi, dünyanın dört bir yanından 200’ü aşkın dili tanıma kapasitesine sahip.
KÜÇÜK EV ALETLERİNDE FIRSATLAR
Teknoblog'un satış ortaklıkları vardır. Bunlar, editoryal içeriği etkilemez, ancak Teknoblog, satış ortaklığı bağlantıları üzerinden satın alınan ürünler için komisyon kazanabilir.